
Scoring forecasts from the 2016 “Expert Survey on Progress in AI”
Patrick Levermore, 1 March 2023
Summary
This document looks at the predictions made by AI experts in The 2016 Expert Survey on Progress in AI, analyses the predictions on ‘Narrow tasks’, and gives a Brier score to the median of the experts’ predictions.
My analysis suggests that the experts did a fairly good job of forecasting (Brier score = 0.19), and would have been less accurate if they had predicted each development in AI to generally come, by a factor of 1.5, later (Brier score = 0.26) or sooner (Brier score = 0.27) than they actually predicted.
I judge that the experts expected 9 milestones to have happened by now - and that 10 milestones have now happened.
But there are important caveats to this, such as:
I have only analysed whether milestones have been publicly met. AI labs may have achieved more milestones in private this year without disclosing them. This means my analysis of how many milestones have been met is probably conservative.
I have taken the point probabilities given, rather than estimating probability distributions for each milestone, meaning I often round down, which skews the expert forecasts towards being more conservative and unfairly penalises their forecasts for low precision.
It’s not apparent that forecasting accuracy on these nearer-term questions is very predictive of forecasting accuracy on the longer-term questions.
My judgements regarding which forecasting questions have resolved positively vs negatively were somewhat subjective (justifications for each question in the separate appendix).
Introduction
In 2016, AI Impacts published The Expert Survey on Progress in AI: a survey of machine learning researchers, asking for their predictions about when various AI developments will occur. The results have been used to inform general and expert opinions on AI timelines.
The survey largely focused on timelines for general/human-level artificial intelligence (median forecast of 2056). However, included in this survey were a collection of questions about shorter-term milestones in AI. Some of these forecasts are now resolvable. Measuring how accurate these shorter-term forecasts have been is probably somewhat informative of how accurate the longer-term forecasts are. More broadly, the accuracy of these shorter-term forecasts seems somewhat informative of how accurate ML researchers' views are in general. So, how have the experts done so far?
Findings
I analysed the 32 ‘Narrow tasks’ to which the following question was asked:
How many years until you think the following AI tasks will be feasible with:
a small chance (10%)?
an even chance (50%)?
a high chance (90%)?
Let a task be ‘feasible’ if one of the best resourced labs could implement it in less than a year if they chose to. Ignore the question of whether they would choose to.1
I interpret ‘feasible’ as whether, in ‘less than a year’ before now, any AI models had passed these milestones, and this was disclosed publicly. Since it is now (February 2023) 6.5 years since this survey, I am therefore looking at any forecasts for events happening within 5.5 years of the survey.
Across these milestones, I judge that 10 have now happened and 22 have not happened. My 90% confidence interval is that 7-15 of them have now happened. A full description of milestones, and justification of my judgments, are in the appendix (separate doc).
The experts forecast that:
4 milestones had a <10% chance of happening by now,
20 had a 10-49% chance,
7 had a 50-89% chance,
1 had a >90% chance.
So they expected 6-17 of these milestones to have happened by now. By eyeballing the forecasts for each milestone, my estimate is that they expected ~9 to have happened.2 I did not estimate the implied probability distributions for each milestone, which would make this more accurate.
Using the 10, 50, and 90% point probabilities, we get the following calibration curve:
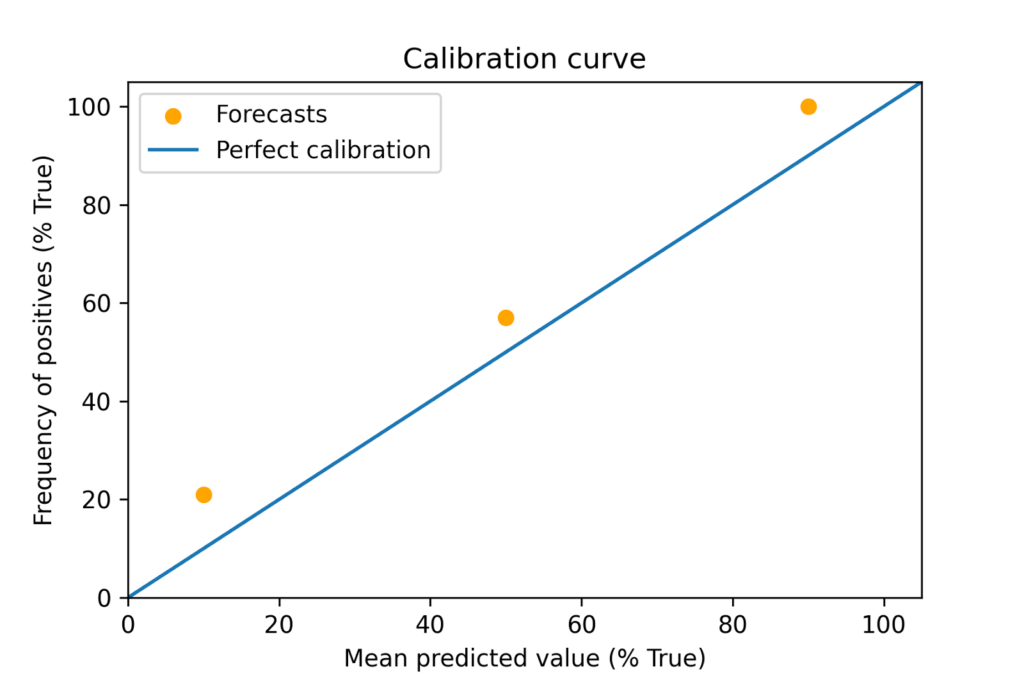
But, firstly, the data here is small (there are 7 data points at the 50% mark and 1 at the 90% mark). Secondly, my methodology for this graph, and in the below Brier calculations, is based on rounding down to the nearest given forecast. For example, if a 10% chance was given at 3 years, and a 50% chance at 10 years, the forecast was taken to be 10%, rather than estimating a full probability distribution and finding the 5.5 years point. This skews the expert forecasts towards being more conservative and unfairly penalises a lack of precision.
Brier scores
Overall, across every forecast made, the experts come out with a Brier score of 0.19.3 The score breakdown and explanation of the method is here.4
For reference, a lower Brier score is better. 0 would mean absolute confidence in everything that eventually happened, 0.25 would mean a series of 50% hedged guesses on anything happening, and randomly guessing from 0% to 100% for every question would yield a Brier score of 0.33.5
Also interesting is the Brier score relative to others who forecast the same events. We don’t have that when looking at the median of our experts - but we could simulate a few other versions:
Bearish6 - if the experts all thought each milestone would take 1.5 times longer than they actually thought, they would’ve gotten a Brier score of 0.27.7
Slightly Bearish - if the experts all thought each milestone would take 1.2 times longer than they actually thought, they would’ve gotten a Brier score of 0.25.
Actual forecasts - a Brier score of 0.19.
Slightly Bullish - if the experts all thought each milestone would take 1.2 times less than they actually thought, they would’ve gotten a Brier score of 0.21.
Bullish - if the experts all thought each milestone would take 1.5 times less than they actually thought, they would’ve gotten a Brier score of 0.26.
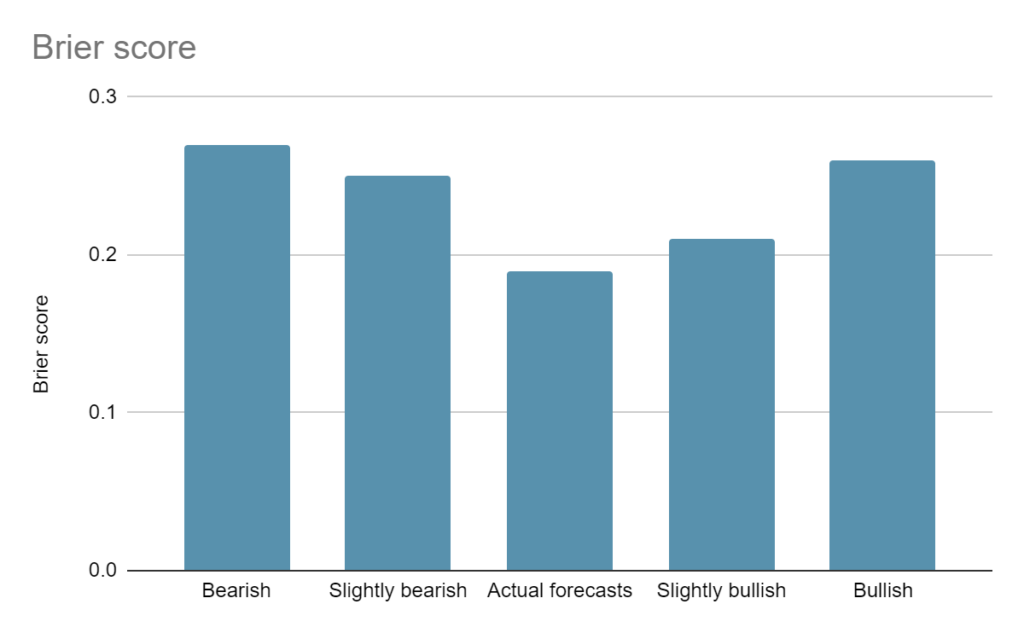
So, the experts were in general pretty accurate and would have been less so if they had been more or less bullish on the speed of AI development (with the same relative expectations between each milestone).
Taken together, I think this should slightly update us towards the expert forecasts being useful in as yet unresolved cases, and away from the usefulness of estimates which fall outside of 1.5 times further or closer than the expert forecasts.
Randomised - if the experts' forecast for each specific milestone were randomly assigned to any forecasted date for a different milestone in the collection, they would've gotten a Bier score of 0.31 (in the random assignment I received from a random number generator).
I think this should update us slightly towards the surveyed experts generally being accurate on which areas of AI would progress fastest. My assessment is that, compared to the experts’ predictions, AI has progressed more quickly in text generation and coding and more slowly in game playing and robotics. It is not clear now whether this trend will continue, or whether other areas in AI will unexpectedly progress more quickly in the next 5 year period.
Summary of milestones and forecasts
In the below table, the numbers in the cells are the median expert response to “Years after the (2016) survey for which there is a 10, 50 and 90% probability of the milestone being feasible”. The final column is my judgement of whether the milestone was in fact feasible after 5.5 years. Orange shading shows forecasts falling within the 5.5 years between the survey and today. A full description of milestones, and justification of my judgments, are in the appendix.
Caveats:
My judgements of which forecasts have turned out true or false are a little subjective. This was made harder by the survey question asking which tasks were ‘feasible’, where feasible meant ‘if one of the best resourced labs could implement it in less than a year if they chose to. Ignore the question of whether they would choose to.’ I have interpreted this as, one year after the forecasted date, have AI labs achieved these milestones, and disclosed this publicly?
Given (a) ‘has happened’ implies ‘feasible’, but ‘feasible’ does not imply ‘has happened’ and (b) labs may have achieved some of these milestones but not disclosed it, I am probably being conservative in the overall number of tasks which have been completed by labs. I have not attempted to offset this conservatism by using my judgement of what labs can probably achieve in private. If you disagree or have insider knowledge of capabilities, you may be interested in editing my working here. Please reach out if you want an explanation of the method, or to privately share updates - patrick at rethinkpriorities dot org.
It’s not obvious that forecasting accuracy on these nearer-term questions is very predictive of forecasting accuracy on the longer-term questions. Dillon (2021) notes “There is some evidence that forecasting skill generalises across topics (see Superforecasting, Tetlock, 2015 and for a brief overview see here) and this might inform a prior that good forecasters in the short term will also be good over the long term, but there may be specific adjustments which are worth emphasising when forecasting in different temporal domains.” I have not found any evidence either way on whether good forecasters in the short term will also be good over the long term, but this does seem possible to analyse from the data that Dillon and niplav collect.8
Finally, there are caveats in the original survey worth noting here, too. For example, how the question is framed makes a difference to forecasts, even when the meaning is the same. To illustrate this, the authors note
“People consistently give later forecasts if you ask them for the probability in N years instead of the year that the probability is M. We saw this in the straightforward HLMI (high-level machine intelligence) question and most of the tasks and occupations, and also in most of these things when we tested them on mturk people earlier. For HLMI for instance, if you ask when there will be a 50% chance of HLMI you get a median answer of 40 years, yet if you ask what the probability of HLMI is in 40 years, you get a median answer of 30%.”
This is commonly true of the 'Narrow tasks' forecasts (although I disagree with the authors that it is consistently so).9 For example, when asked when there is a 50% chance AI can write a top forty hit, respondents gave a median of 10 years. Yet when asked about the probability of this milestone being reached in 10 years, respondents gave a median of 27.5%.
What does this all mean for us?
Maybe not a huge amount at this point. It is probably a little too early to get a good picture of the experts' accuracy, and there are a few important caveats. But this should update you slightly towards the experts’ timelines if you were sceptical of their forecasts. Within another five years, we will have ~twice the data and a good sense of how the experts performed across their 50% estimates.
It is also limiting to have only one comprehensive survey of AI experts which includes both long-term and shorter-term timelines. What would be excellent for assessing accuracy is detailed forecasts from various different groups, including political pundits, technical experts, and professional forecasters, with which we can compare accuracy between groups. It would be easier to analyse the forecasting accuracy of the questions focused on what developments have happened, rather than what developments are feasible. We could try closer to home, maybe the average EA would be better at forecasting developments than the average AI expert - it seems worth testing now to give us some more data in ten years!

This is a blog post, not a research report, meaning it was produced quickly and is not to our typical standards of substantiveness and careful checking for accuracy. I’m grateful to Alex Lintz, Amanda El-Dakhakhni, Ben Cottier, Charlie Harrison, Oliver Guest, Michael Aird, Rick Korzekwa, and Zach Stein-Perlman for comments on an earlier draft.
If you are interested in RP’s work, please visit our research database and subscribe to our newsletter.
Cross-posted to EA Forum, Lesswrong, and this google doc.
I only analysed this ‘fixed probabilities’ question and not the alternative ‘fixed years’ question, which asked:
“How likely do you think it is that the following AI tasks will be feasible within the next:
- 10 years?
- 20 years?
- 50 years?”
We are not yet at any of these dates, so the analysis would be much more unclear.
9 = 4*5% + 14*15% + 6*30% + 5*55% + 2*80% + 1*90%
A precise number as a Brier score does not imply an accurate assessment of forecasting ability - ideally, we could work with a larger dataset (i.e. more surveys, with more questions) to get more accuracy.
My methodology for the Brier score calculations is based on rounding down to the nearest given forecast, or rounding up to the 10% mark. For example, if a 10% chance was given at 3 years, and a 50% chance at 10 years, the forecast was taken to be 10%, rather than estimating a full probability distribution and finding the 5.5 years point. This skews the expert forecasts towards being more conservative and unfairly penalises them. If the experts gave a 10% chance of X happening in 3 years, I didn’t check whether it had happened in 3 years, but instead checked if it had happened by now. I estimate these two factors (the first skewing the forecasts to be more begives a roughly balance 5-10% increase to the Brier score, given most milestones included a probability at the 5 year mark. A better analysis would estimate the probability distributions implied by each 10, 50, 90% point probability, then assess the probability implied at 5.5 years.
For more detail, see Brier score - Wikipedia.
By ‘bearish’ and ‘bullish’ I mean expecting AI milestones to be met later or sooner, respectively.
This seems valuable, and I’m not sure why it hasn’t been analysed yet.
Somewhat relevant sources:https://forum.effectivealtruism.org/posts/hqkyaHLQhzuREcXSX/data-on-forecasting-accuracy-across-different-time-horizonshttps://www.lesswrong.com/posts/MquvZCGWyYinsN49c/range-and-forecasting-accuracyhttps://www.openphilanthropy.org/research/how-feasible-is-long-range-forecasting/https://forum.effectivealtruism.org/topics/long-range-forecasting
I sampled ten forecasts where probabilities were given on a 10 year timescale, and five of them (Subtitles, Transcribe, Top forty, Random game, Explain) gave later forecasts when asked with a ‘probability in N years’ framing rather than a ‘year that the probability is M’ framing, three of them (Video scene, Read aloud, Atari) gave the same forecasts, and two of them (Rosetta, Taylor) gave an earlier forecast. This is why I disagree it leads to consistently later forecasts.
 | A guest post by
|